The rapid development of AI has steadily advanced the field of text-to-video (T2V) generation, offering a rich and convenient video content creation experience and unlocking new possibilities in entertainment, education, and multimedia communication. Traditional T2V methods, however, are limited due to a lack of data and computational resources, making it difficult to generate long videos (longer than 30 seconds) that contain dynamic content and temporal consistency. Achieving coherence and preserving the dynamics when generating long videos while also improving efficiency has become a key focus in this field.
To address this, a research team at Microsoft Research Asia has developed the ARLON framework, which combines autoregressive (AR) models with diffusion transformer (DiT) technology. By using vector quantized variational autoencoder (VQ-VAE) technology, ARLON effectively compresses and quantizes high-dimensional input features in T2V tasks, reducing learning complexity without compromising information density. With text prompts, ARLON synthesizes high-quality videos that retain both rich dynamics and temporal coherence.
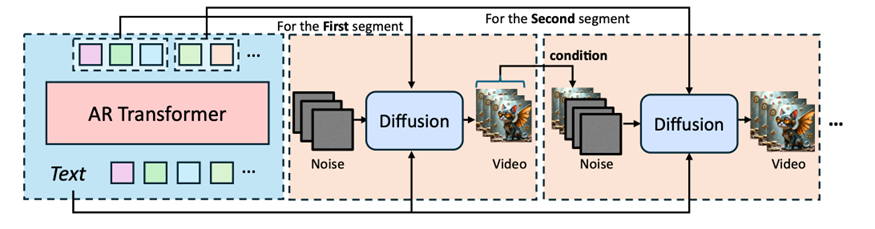
They optimized the ARLON framework by introducing an adaptive semantic injection module and an uncertainty sampling strategy, enhancing the model’s robustness to noise and improving the efficiency of video generation. The adaptive semantic injection module uses a gated adaptive normalization mechanism to inject coarse semantic information into the video generation process. Meanwhile, an uncertainty sampling strategy simulates errors in AR predictions by sampling noise from the distribution of the original coarse latent features, improving the model’s adaptability to different input conditions.
Evaluation demonstrates that ARLON can significantly outperform earlier video generation models in robustness, naturalness, and dynamic consistency. Even when handling highly complex or repetitive scenes, it can consistently synthesize high-quality videos. Using the VBench video generation benchmark, ARLON surpassed existing baseline models and achieved groundbreaking progress across multiple evaluation metrics. The success of the ARLON framework demonstrates the potential of combining the strengths of different models to solve complex problems and offers new directions for advancing video generation technology.
How ARLON enhances the efficiency and quality of long video generation
The ARLON framework is composed of three primary components: latent VQ-VAE compression, AR modeling, and semantic-aware condition generation. Given a text prompt, the AR model predicts coarse visual latent tokens, constructed from a 3D VAE encoder followed by a latent VQ-VAE encoder. These predicted visual latent tokens encapsulate both coarse spatial information and consistent semantic information. Based on these tokens, a latent VQ-VAE decoder generates continuous latent features, which serve as semantic conditions to guide the DiT model with a semantic injection module.
These components are described in detail below:
Latent VQ-VAE compression is a crucial step maps high-dimensional input features into a compact and discrete latent space. The process is achieved through the following expression:

where X∈R^(T×H×W×C) represents the input features, E_”latent” is the encoder composed of 3D convolutional neural network blocks and residual attention blocks, and V∈R^(T/r×H/o×W/o×h) is the encoded latent embedding. Each embedding vector v∈R^h is quantized to the nearest entry c∈R^m in the codebook C∈R^(K×m), forming the discrete latent embedding (Q):

The decoding process involves retrieving the corresponding entries (c) from the codebook (C) given the indices of the video tokens and then using the latent VQ-VAE decoder to reconstruct the video embeddings (F):

AR modeling uses a causal transformer decoder as a language model, combining the text condition Y and the indices of visual tokens Q as the input to the model to generate video content in an AR manner. This process can be described by the following probabilistic model:

where Q_”AR” =[q_1,q_2,…,q_N ] is the sequence of visual token indices, and N is the sequence length. Θ“AR” represents the model parameters. The objective of the model is to maximize the probability of the visual token index sequence Q“AR” given the text condition Y.
In the semantic-aware condition generation phase, the ARLON framework utilizes a video VAE and a latent VQ-VAE to compress the video into a coarse latent space. It uses the tokens predicted by the AR model as semantic conditions for training the diffusion model. This process can be represented by:
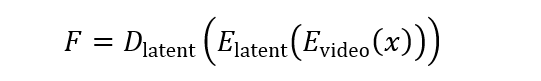
where x is the input video, E_”video” is the video encoder, E_”latent” is the latent VQ-VAE encoder, D_”latent” is the latent VQ-VAE decoder, and F is the reconstructed latent feature used as the semantic condition.
Semantic injection involves injecting coarse semantic information into the video generation process to guide the diffusion process. This involves the following steps:

where X_i is the input latent variable, F ̂_i is the condition latent variable processed by uncertainty sampling, α_i,β_i,γ_iare the scale, shift, and gating parameters generated by the multi-layer perceptron (MLP ) network, and the “Fusion” function injects the condition information into the original latent variable.
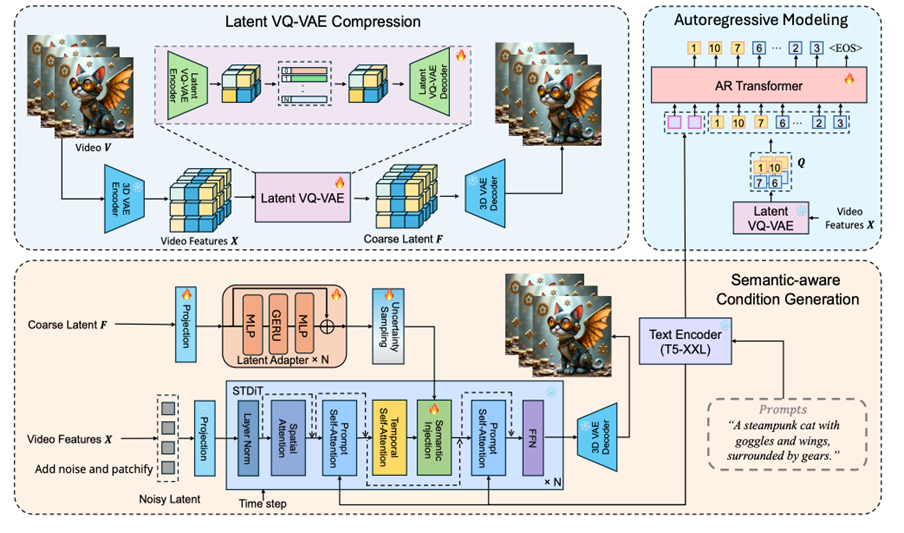
To mitigate the inevitable noise introduced during AR inference, the team adopted the following two strategies during the training phase:
Coarse visual latent tokens: Two different compression ratios of latent VQ-VAE for training and inference enhance the diffusion process’s tolerance to noisy AR predictions.
Uncertainty sampling: To simulate the variance of AR predictions, an uncertainty sampling module was introduced. This generates noise from the distribution of the original coarse latent features F_i rather than strictly relying on the original coarse latent features:
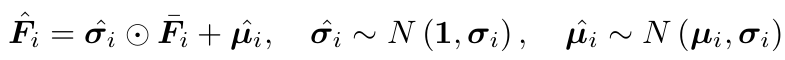
where μ_i and σ_i are the mean and standard deviation of the noises, respectively, and F ‾_i=(F_i-μ_i)/σ_i is the normalized feature. σ ̂_i and μ ̂_i are noise vectors sampled from the target feature mean and variance distribution.
Evaluation results
The team assessed ARLON against other open-source text-to-long-video generation models using VBench metrics, such as dynamic degree, aesthetic quality, imaging quality, subject consistency, overall consistency, background consistency, and motion smoothness. ARLON achieved state-of-the-art performance in long video generation, with significant improvements in both inference efficiency and generation quality. The results, shown in Figure 3, demonstrate that ARLON excels across multiple evaluation metrics, particularly in dynamic degree and aesthetic quality.

Qualitative results further highlight ARLON’s ability to maintain both dynamism and consistency in generated videos. Unlike models that generate static or nearly motionless videos, ARLON achieves a better balance among dynamic motion, temporal consistency, and natural smoothness. Its videos retain a high level of subject consistency while exhibiting fluid and lifelike motion.



ARLON significantly accelerates the DiT model’s denoising process by using AR-predicted latent features as an effective initialization. While the baseline model requires 30 steps for denoising, ARLON achieves similar performance in just 5 to 10 steps.

Additionally, ARLON supports long video generation through progressive text prompts, enabling the model to generate videos based on a series of gradually changing text prompts while preserving the coherence of the video content during prompt transitions.


Note: ARLON (opens in new tab) is a research project. While it can synthesize long videos with dynamic scenes, their realism and naturalness depend on factors such as the length, quality, and context of the video prompts. The model carries potential risks of misuse, including forging video content or impersonating specific scenes. In video generation research, applying the model to new, real-world scenarios requires agreements with relevant stakeholders for the use of video content and the integration of synthetic video detection models. If you suspect that ARLON is being misused, used illegally, or infringing on your rights or the rights of others, report it through the Microsoft abuse reporting portal (opens in new tab).
The rapid development of AI has made trustworthy AI systems an urgent issue. Microsoft has taken proactive measures to anticipate and mitigate risks associated with AI technologies and is committed to promoting the development of AI in accordance with human-centered ethical principles. In 2018, Microsoft introduced six Responsible AI Principles: fairness, inclusiveness, reliability and safety, transparency, privacy and security, and accountability. These principles were later formalized through the Responsible AI Standards, supported by a governance framework to ensure that Microsoft teams integrate them into their daily workflows. Microsoft is continuing to collaborate with researchers and academic institutions worldwide to advance responsible AI practices and technologies.