

编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
12月10日至12月15日,全球最负盛名的人工智能盛会之一 NeurIPS 大会将在加拿大温哥华举办。因此,我们将通过三期“科研上新”为大家带来多篇微软亚洲研究院入选 NeurIPS 2024 的精选论文解读,涉及内容涵盖大模型优化、生成式人工智能、社会责任人工智能、跨模态学习、特定领域基础模型等。
增强和提高大语言模型(LLMs)的能力与效率是推动人工智能技术进步的关键。在第一期 NeurIPS 2024 精选论文解读中,大家将了解到微软亚洲研究院的研究员们不仅通过提升 LLMs 的逻辑推理、鲁棒性和组合能力来拓宽其应用边界,从而应对日益复杂的任务,同时,也在探索提高速度和优化资源利用率的方法,使 LLMs 更实用、更易于被广泛采用。
本期内容速览
01. BPQP:一种用于高效端到端学习的可微分凸优化框架(Spotlight)
02. 图学习可以提升大语言模型智能体的规划能力吗?
03. ERBench:自动可验证的大模型幻觉评测框架(Spotlight)
04. 大模型的“心灵之眼”,VoT激发大语言模型的空间推理能力
05. MInference 1.0:助力长上下文大语言模型高效推理的动态稀疏注意力解决方案(Spotlight)
06. YOCO:打破传统Decoder-only架构(Oral)
07. xRAG:基于模态融合的高效检索增强生成框架
01. BPQP:一种用于高效端到端学习的可微分凸优化框架

论文链接:https://arxiv.org/abs/2411.19285 (opens in new tab)
GitHub 链接:http://github.com/microsoft/qlib
近年来,深度神经网络被越来越多地用于解决数据驱动的决策问题。但在很多场景中,为了满足工业场景的各种约束,直接端到端地学习并生成最终决策存在困难。这类问题在最后进行决策的时候常常需要进行带有约束的凸优化问题(在投资组合优化、控制系统和信号处理等领域很常见)。解决该问题的一类方法是选择进行两个阶段的优化,先对一些中间未知变量进行预测,最后再生成决策。这种分阶段优化相比于端到端优化,容易与最终目标出现偏差。所以又出现了各种方法,将决策模块变成一个可学习的神经网络层来直接端到端地学习。
实现这种优化层的内部蕴含着一个凸优化问题,它通常缺乏通用的闭式解,因此,计算相关参数的梯度需要更复杂的方法。使用隐函数定理进行优化、实现梯度传导支持端到端学习是相对精确、高效的技术方向。但是这种技术在较大规模的数据上仍然存在性能瓶颈。
对此,研究员们在这一技术方向上提出了一个通用的、一阶可微分的凸优化框架 Backward Pass as a Quadratic Programming(BPQP)。具体来说,BPQP 通过将一阶条件矩阵重新表述为一个简单的二次规划(QP)问题,简化了优化层参数的反向传播(BP)。同时,这也将前向和反向传播解耦,并创建了一个可以利用的现有高效求解器框架。简化和解耦反向传播显著降低了前向和反向传播的计算成本。
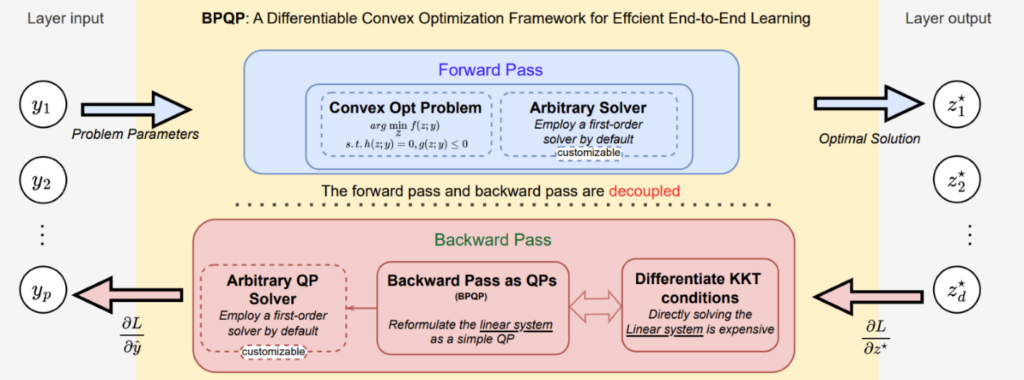
实验结果显示,BPQP 大大减少了整体计算时间,在100维线性规划、二次规划和二阶锥规划上分别实现了高达13.54倍、21.02倍和1.67倍的性能提升。这种效率的提高为 BPQP 在大规模真实世界端到端学习场景中的应用铺平了道路。
02. 图学习可以提升大语言模型智能体的规划能力吗?

论文链接:https://arxiv.org/abs/2405.19119 (opens in new tab)
代码链接:https://github.com/WxxShirley/GNN4TaskPlan (opens in new tab)
随着技术的快速发展,大语言模型智能体如今已经可以充当个人助手、自动打游戏、自动进行一些科学发现了。在这些应用中,规划能力必不可少。本篇40页的论文以工具智能体为例,第一次研究了图建模与图学习能否提升大语言模型的推理规划能力。
大模型的推理规划一般是把一个复杂的问题拆解为若干个简单的问题,然后逐一解决。比如,在 JARVIS 中,把用户的需求拆解为可以被 HuggingFace 上的 API 解决的需求。而图建模可以把子任务看成图上的节点,任务之间的依赖性看成图上的边。然后,规划就是在图上找到一个路径或者子图来满足用户需求,可以看作是一个图上的决策问题。

研究员们测试了四种图方法:(1) 图提示词、(2)长推理过程、(3)具有图输入能力的语言模型、(4) 用图神经网络完善大模型的输出,发现四种方法都能提升语言模型的规划能力,其中方法(4)效果最佳。此外,研究员们还证明了 Transformer 拥有足够的表达能力可以解决图决策问题,但自然语言和自回归损失函数的归纳偏置影响了它的整体性能。
实验结果显示,在 zero-shot 和带训练的场景下,规划性能都得到了极大的提升,在 ultratool 上 Llama 模型任务的完成率从13%提升到了28%,GPT-4 的任务完成率从28%提升到了37%。
03. ERBench:自动可验证的大模型幻觉评测框架

论文链接:https://arxiv.org/abs/2403.05266 (opens in new tab)
代码链接:https://github.com/DILAB-KAIST/ERBench (opens in new tab)
近年来,大语言模型的生成能力和应用场景不断扩展。然而,“幻觉”问题一直是科研人员和开发者面临的一大挑战。所谓幻觉,是指模型生成虚假、未经验证或不存在的信息,尤其在知识密集型或安全关键型的应用中,这一问题尤为突出。这不仅削弱了模型的可靠性,还使模型在实际场景中的应用也受到了限制。
为此,韩国科学技术院(KAIST)与微软亚洲研究院联合开发了一种名为 ERBench(Entity-Relationship Benchmark)的新方法。该方法利用实体关系模型(ER Model)构建了一个基准测试框架,为幻觉评估提供了新的视角。
传统评估方法主要依赖于手工构建的基准测试集或自动生成的知识图谱问答任务。这些方法面临构建成本高、不可扩展的问题,或者问题过于简单,无法深入评估模型的推理过程。ERBench 首次将关系型数据库引入 LLMs 评估,通过功能依赖(functional dependency, FD)和外键约束(foreign key constraint, FKC)两个关键特性实现了评估方法的创新。其中,功能依赖通过关系模式中属性之间的依赖关系生成复杂、层次分明的问答任务;外键约束则允许多个表之间的联合查询,生成多跳推理问题。通过这两种机制,ERBench 能够自动生成可验证的单选、多选甚至多模态问题,并对模型答案和推理过程进行精确评估。

在实验中,ERBench 使用了电影、足球、机场、音乐和图书五大领域的公共数据库构建评估集。实验结果显示,ERBench 不仅关注答案的正确性,还进一步验证了推理过程中关键词的正确性,这种“双重验证”有效捕捉了模型潜在的幻觉问题。此外,ERBench 支持评估集的自动扩展,可适配多模态数据以及多种提示工程技术,展现了其扩展性与实时性。
尽管 ERBench 作为基于实体关系模型的大模型评估框架,开辟了新的研究方向,但其依赖数据库完整性约束进行验证的机制也存在局限性,尤其是在数据库数据质量较低或完整性约束不足的情况下,可能会影响评估的准确性。未来,ERBench 将探索全面推理验证、跨领域应用以及模型优化反馈等方向。
04. 大模型的“心灵之眼”,VoT激发大语言模型的空间推理能力

论文链接:https://arxiv.org/abs/2404.03622 (opens in new tab)
项目主页:https://microsoft.github.io/visualization-of-thought (opens in new tab)
人类具有通过“心灵之眼” (Mind’s Eye)来想象未见之物的认知能力,这使得我们能够在脑海中构建复杂的空间关系和场景布局。虽然大语言模型在语言理解和各种推理任务上取得了令人瞩目的成果,但它们在空间推理方面的能力尚未得到充分探索。受“心灵之眼”能力的启发,研究员们提出了一种名为“思想可视化”(VoT)的新型提示方法,旨在激发 LLMs 的空间推理能力。
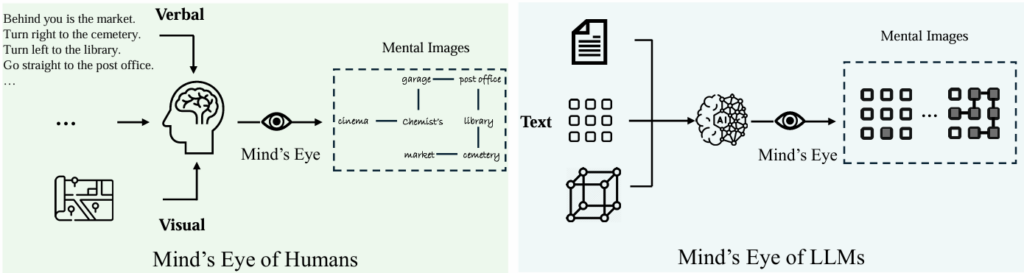
VoT 提示方法的核心思想是让 LLMs 在每个推理步骤中生成当前状态的可视化结果,从而指导后续的推理。这种方法不依赖样本示例或基于文本的图像生成技术,而是利用 LLMs 自身的能力使用文本字符进行推理状态的可视化。研究员们分析认为,这种能力的来源可能与 LLMs 在代码预训练过程中的代码注释有关,这其中包含了特殊字符 ASCII Art 构成的视觉表示,这些数据可能增强了 LLMs 在空间理解和视觉化方面的泛化能力。
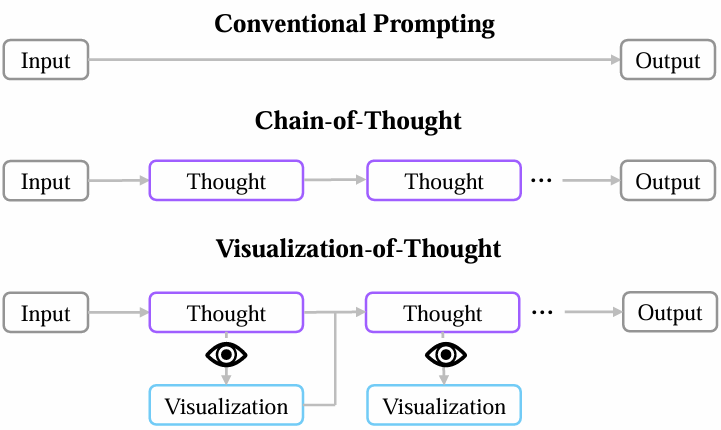
为了验证 VoT 的有效性,研究员们在三个涉及多步空间推理的任务上进行了测试,包括自然语言导航、二维网格中的导航与拼图。实验结果显示,VoT 显著提升了 LLMs 在这些任务上的表现,甚至超越了当前 SOTA 的多模态大语言模型。
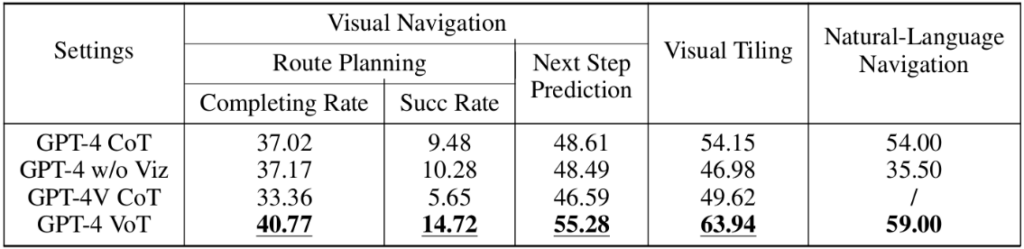
研究员们分析了 LLMs 在这些任务中的推理过程,可以发现:在二维网格导航任务中,模型通过可视化路径有效避开了障碍物;在拼图任务中,模型会尝试拼接形状来判断可行性;在自然语言导航任务中,模型则能根据自然语言描述重建地图,并模拟出相应的运动轨迹。由此可见,“思想可视化”(VoT)提示方法为 LLMs 的空间推理能力带来了突破性提升,同时为 LLMs 的能力扩展提供了新的视角。



05. MInference 1.0:助力长上下文大语言模型高效推理的动态稀疏注意力解决方案

论文链接:https://arxiv.org/abs/2407.02490 (opens in new tab)
项目链接:https://aka.ms/MInference (opens in new tab)
代码链接:https://github.com/microsoft/MInference (opens in new tab)
Demo链接:https://huggingface.co/spaces/microsoft/MInference (opens in new tab)
长文本处理已成为大语言模型的标配功能,其支持的上下文长度逐步从128K扩展至10M。这一进步解锁了众多下游应用场景,包括仓库级代码理解、长文档问答、自我对弈推理以及长历史任务 agent 等。然而,长文本大语言模型的推理开销十分巨大,尤其是在预填充阶段,由于注意力机制的平方复杂度特性,随着上下文长度增加,延迟会呈指数级增长。以 Llama-3-8B 模型为例,在单张 A100 GPU 上运行时,处理300K上下文需要3分钟,而处理1M上下文则需耗时30分钟。
为了解决这一问题,研究员们开发了 MInference 1.0,通过引入动态稀疏注意力机制显著加速了长上下文 LLMs 的预填充阶段。MInference 1.0 的核心在于利用注意力矩阵中的三种稀疏模式(A 形模式、垂直斜线模式和块稀疏模式)动态构建稀疏索引,并通过优化的 GPU 内核实现高效稀疏计算。相比现有方法,MInference 无需改变模型的预训练设置或额外微调,直接适配即可。
具体而言,MInference 利用长上下文大语言模型中注意力矩阵的动态稀疏特性,将其归纳为三种 GPU 内核友好的模式。通过离线识别最优注意力模式,在推理时动态生成稀疏索引,并基于 PIT、Triton 和 FlashAttention 等工具开发的 GPU 内核,大幅减少稀疏注意力计算的浮点运算量(减少95%)。

MInference 1.0 目前的主要成果有:一,显著降低首字时延(TTFT),在单张 A100 GPU 上,MInference 将处理100万标记提示的时间从30分钟缩短至3分钟,实现了高达10倍的速度提升;二,保持高精度,在一系列任务(如 InfiniteBench、RULER、PG-19 等)中,MInference 与基线方法相比无明显精度损失,甚至在部分任务中表现更佳;三,优化通用性,适用于多种模型(如LLaMA-3-1M、GLM-4-1M、Qwen2、Phi-3),无论是单任务还是多任务场景,均表现优异。
06. YOCO:打破传统Decoder-Only架构

论文链接:https://arxiv.org/abs/2405.05254 (opens in new tab)
微软亚洲研究院推出了一种创新性的 Decoder-Decoder 架构 YOCO(You Only Cache Once)。通过自解码器和交叉解码器的独特架构,YOCO 仅需缓存一次键值对,从而显著降低 GPU 内存的使用。在模型评估中,YOCO 展现出与同规模 Transformer 模型相媲美的性能,并在语言建模评估、模型大小扩展以及长上下文处理方面具有显著优势。特别是在降低 GPU 内存占用和缩短预填充延迟方面,YOCO 实现了线性复杂度的预填充延迟,并成量级地减少了键值对内存需求,为大语言模型下一代架构指明了方向。
了解更多详情:《YOCO:打破传统Decoder-only架构,内存消耗仅为Transformer的六分之一》 (opens in new tab)
07. xRAG:基于模态融合的高效检索增强生成框架

论文链接:https://nips.cc/virtual/2024/poster/96497 (opens in new tab)
GitHub 链接:https://github.com/Hannibal046/xRAG (opens in new tab)
检索增强生成(RAG)近来在知识密集型任务中展现出了显著优势,其通过从非参数知识库中检索领域特定及最新信息,将语言模型的能力扩展到了更广泛的问题解答和推理任务中。然而,传统 RAG 方法由于直接将整篇文档插入提示中,不仅显著增加了推理时的计算成本,还面临模型上下文长度的限制。例如,在生成准确回复时,模型需要处理包含原始查询及多倍扩展文档的上下文,带来了推理效率上的巨大挑战。
为应对这些问题,微软亚洲研究院的研究员们提出了一种创新的上下文压缩方法 xRAG,专为检索增强生成任务设计。不同于传统压缩方法关注于文档的表面形式(如LLMLingua、AutoCompressor),xRAG 从多模态融合的视角重新定义了文档嵌入的使用方式。通过独特的检索模态特征方法,xRAG 可以将原本用于检索的文档高维嵌入直接融合到语言模型的表示空间中,无需再引用文档的文本内容,从而实现了极高的压缩率(从数百个 Token 压缩为单个 Token)。

在 xRAG 的设计中,检索器和语言模型均保持冻结状态,只通过一个小型的 modality bridge 实现特征整合。这一设计不仅支持离线使用预构建的文档嵌入,还维护了 RAG 系统的即插即用属性。在训练阶段,xRAG 采用了两阶段的优化策略——段落重述预训练及上下文感知指令微调,从而提升了模型对嵌入特征的理解与利用能力。

实验结果显示,在广泛的知识密集型任务测试中(如 Open-Domain QA、Multi-hop QA 等),xRAG 在大幅降低计算成本的情况下,性能持续超过现有压缩方法,甚至在部分数据集上达到了与未压缩模型相当的水平。详细分析表明,其在减少推理开销方面表现突出,与传统 RAG 模型相比,xRAG 平均减少了3.53倍的 FLOPs,同时推理速度提升约1.64倍。更重要的是,xRAG 在面对冗余或误导性检索内容时表现出了更高的鲁棒性,较大程度上避免了因错误检索内容导致的回答偏差。



