

编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
CHI 是人机交互领域最具影响力的国际顶级会议之一,今年的 CHI 大会于4月26日至5月1日在日本横滨举办。本期“科研上新”将为大家带来微软亚洲研究院入选 CHI 2025 的三篇精选论文,聚焦生成式 AI 驱动下的设计协同与人机交互前沿探索。
本期内容速览
01. ProductMeta:基于多模态大语言模型的交互式隐喻性产品设计创意系统
02. 交互增强型指令:打开生成式AI精准协作的新范式
03. 数据视频工具设计范式的系统性反思
01. ProductMeta:基于多模态大语言模型的交互式隐喻性产品设计创意系统

隐喻性产品设计是指通过将“喻体”(某一物体)的属性映射到“本体”(待设计产品)上,来增强产品的新颖性、激发情感共鸣,并提升用户体验。但新手设计师在这一过程中往往面临三大难题:一是难以想到有创意且符合设计情境的喻体;二是映射维度繁多,容易遗漏关键属性;三是在隐喻表达与产品可用性之间很难取得平衡。
为此,微软亚洲研究院联合清华大学和乔治梅森大学的研究人员提出了一款基于多模态大语言模型的隐喻性产品设计创意支持工具 ProductMeta。通过“分步+框架化”的交互界面,ProductMeta 可以把隐喻设计的过程拆解为三大模块:喻体探索、映射探索与方案构建,从而辅助设计师在发散与收敛思维之间无缝切换,生成多样且契合情境的隐喻化设计方案。

在喻体探索阶段,系统首先对本体产品进行感官(视觉、触觉、声音等)、行为和反思层面的特征分析,然后基于诺曼情感化设计的“本能层—行为层—反思层”框架自动生成多样化的喻体,并以可视化的“隐喻卡片”形式进行呈现。每张隐喻卡片不仅展示喻体名称与关联描述,还配有示意图,设计师可悬停查看更深入的使用场景、情感意义及可能的映射策略。这一设计大大降低了设计师在灵感发散阶段的信息检索成本,帮助他们迅速获得高质量、契合语境的创意来源。

进入映射探索时,ProductMeta 以“本体的…属性+以…方式+如同喻体的…属性”的三栏面板,引导设计师在视觉、触觉、声音、气味等多种感官维度上进行系统化尝试。配合“概念库”,设计师可以将心仪的映射策略快速细化为设计概念,并在同一界面中对比管理。此外,系统还支持上传自选的喻体或本体图片,通过内置的属性提取功能自动识别并补充特征,确保映射探索符合设计意图。
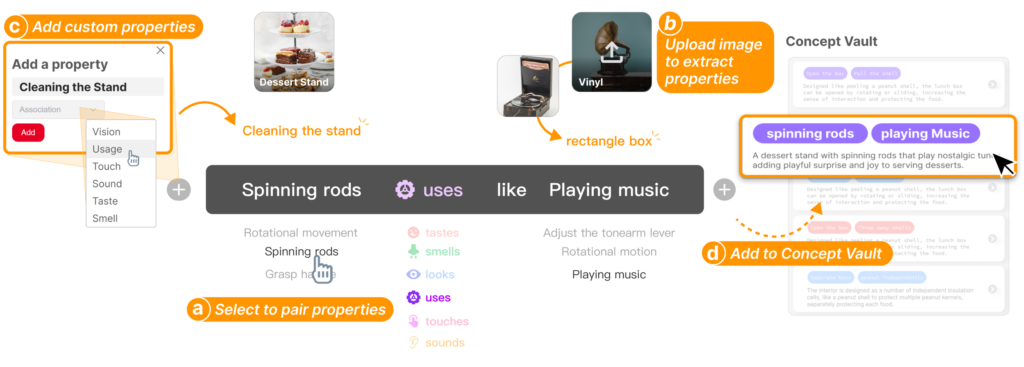
在方案构建阶段,ProductMeta 通过“约束面板”与“属性面板”分别分解本体的功能-行为-结构要素与喻体的形式、色彩、材质等细节,帮助设计师在隐喻表达与产品可用性之间找到平衡。基于先前选定的映射策略与关键词,系统可一次性生成四套设计方案,包含设计名称、宣传语、概念描述和产品渲染图,为设计师提供多元化的参考视角。用户可根据需要反复调整关键词或上传新图片,迅速获得迭代更新的设计方案。

在一项包含16名初学设计师的对比实验中,ProductMeta 相较于基于 GPT4o 的 ChatGPT 接口,在创意喻体多样性、映射策略深度以及方案可行性上均表现出显著优势。使用者报告显示,ProductMeta 不仅提升了探索的广度与迭代的频次,也增强了对过程的掌控感与投入度。专家评审进一步证实,借助 ProductMeta 所生成的隐喻性设计方案在创新性与实用性方面均优于对照组成果。
未来,研究员们计划在多模态属性提取与生成、交互流程及体验等方面持续优化,并探索将该工具与更多场景的具体需求相结合,进一步提升隐喻性产品设计的验证与迭代效率。

02. 交互增强型指令:打开生成式AI精准协作的新范式

论文链接:https://arxiv.org/abs/2503.02874 (opens in new tab)
生成式人工智能的普及让自然语言指令成为人机交互的核心方式,但其固有的模糊性常导致输出偏离用户的真实需求。为破解这一困局,微软亚洲研究院联合香港科技大学、西北大学的研究团队在最新论文中系统阐释了“交互增强型指令(Interaction-Augmented Instruction)”的设计逻辑与应用框架,为提升 AI 意图理解能力提供了理论支撑。
此前给 AI 下指令就像恋爱中的纯文字表白,若加入”肢体语言”效果可能会更好。顶级的专业用户也都在使用”文字+交互”的组合拳:设计师用涂抹选区精准锁定修改区域,程序员用流程图框定代码生成范围等。尽管这种增强策略已经被广泛应用,但目前仍缺乏对其设计范式的系统性理解,这在一定程度上阻碍了相关技术的重用与创新。
为此,研究团队提出了智能指令设计的五大灵魂拷问 4W1H:
1. Why:为什么需要交互助攻?
限制范围:给 AI 画个”重点圈”,避免系统乱涂鸦
扩展信息:给提示词”打补丁”,生成 BGM 时可直接拖入参考音频
重组结构:把“碎碎念”变成思维导图
修正表达:给模糊描述“上滤镜”,秒变具体参数
2️. When:何时发起交互?
起手式:开局就画重点
见招拆招:根据 AI 反馈动态调整
3️. Who:谁来主导这场对话?
用户主动派:拖拽/标注/草图任选
AI 助攻流:智能推荐选项的多轮 battle
4️. What:有哪些神仙操作?
从基础款到 Pro 版:点击选择、文本标注、手绘草图、流程图操控、3D 空间标注等等
5️. How:如何落地执行?
AI 直接解码或调用其他专业工具链(PS/Sketch 全家桶联动)
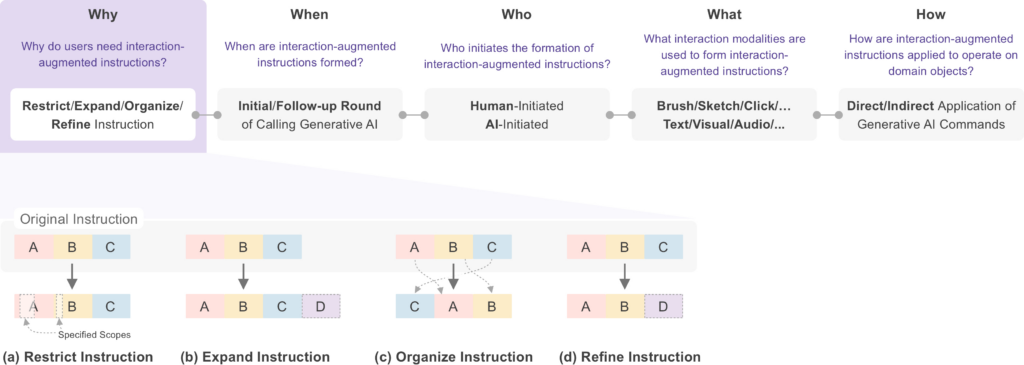
借助 4W1H 框架,本文详细分析了支持交互增强型指令的现有工具,并总结了常见的设计范式。基于这些洞见,研究团队还提出了一系列潜在的研究机会,比如更深入的理解和评估大模型对于人机交互方式的支持,以及不同设计范式对用户在人机协同(Human-AI Collaboration)过程中认知和自主性的影响。

03. 数据视频工具设计范式的系统性反思

论文链接:https://arxiv.org/abs/2502.04801 (opens in new tab)
数据视频作为一种融合可视化、动画与音频的多媒体叙事形式,近年来在商业、教育及设计领域迅速普及。其核心优势在于通过动态化叙事降低数据理解门槛,并借助多感官刺激提升观众参与度。几大全球知名的视频内容平台均验证了数据视频的亿级用户吸引力。然而,视频的创作过程复杂,需协调可视化、动画、叙事结构、音频等多样的多媒体组件,对用户的设计能力和工具支持提出了极高的要求。尽管已有大量工具致力于简化流程,但仍缺乏对设计范式的系统性总结,难以指导未来工具的开发。
为此,微软亚洲研究院的研究员们与香港科技大学屈华民教授的团队提出了一个二维框架,从“创建与协调什么样的数据视频组件”和“如何高效地支持创建与协调这些组件”两个维度,对46个现有数据视频工具的表现力(expressiviness)和可学习性(learnability)进行了深度分析。
数据视频可分解为视觉、动效、叙事、音频四类组件,按组件复杂度研究员们将其划分为三个表现力层级:动画单元(视觉+动效)、动态叙事(增加文本)、音频增强视频(包含完整四要素)。

现有工具通过差异化来分配人机任务,以促进各组件的创作与协同。从用户输入到最终协调数据视频组件的转化过程呈现出四种人机分工模式:原始模式(无转化)、人工主导(用户全流程控制)、混合主导(人机协同)及 AI 主导(自动化生成)。
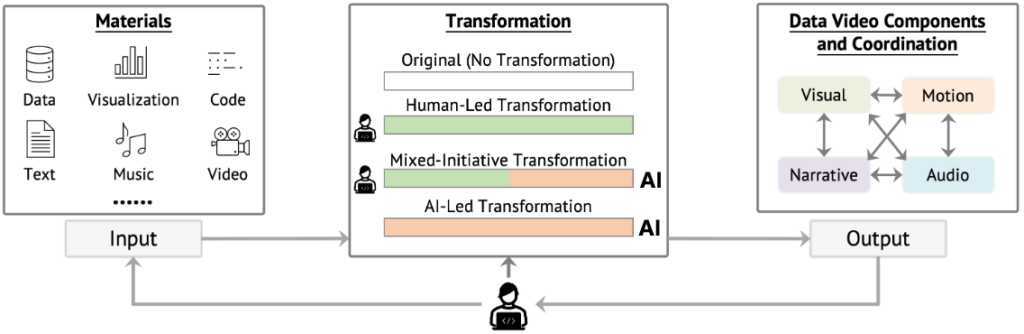
在此框架下,研究员们剖析了现有工具如何以更低认知负荷辅助用户完成各组件的创作与协调,并提炼出每种转化模式下的关键设计范式。最后,研究员们对数据视频制作进行了整体性审视,揭示了各个阶段存在的空白,并探讨了应对这些空白的潜在方向,旨在加深对当前数据视频创作实践的理解,推动更高效、更有效的工具和方法论的发展。




