

A key challenge, and opportunity, of large language models (LLMs) is bridging the gap between their training data and the vast amount of unfamiliar information they encounter in real-world applications. Successfully navigating this divide could unlock a new era of data analysis, helping these models to uncover nuanced themes and semantic concepts across a wide array of datasets with unprecedented precision.
Retrieval-Augmented Generation (RAG), a technique combining information retrieval with text generation, has emerged in recent years as a promising solution to enhance LLMs’ performance on new data. It allows LLMs to access and utilize external, up-to-date, or specialized information when responding to queries, expanding the potential for data investigation and enabling more accurate and enabling more accurate analysis across various domains.
However, even with RAG, LLMs struggle in real-world industrial applications, which present unique and complex challenges. Information retrieval alone cannot extract deep insights from domain-specific datasets or perform the logical reasoning required for nuanced decision-making.
To address this, we propose PIKE-RAG (opens in new tab) (Specialized Knowledge and Rationale Augmented Generation), a method designed to understand, extract, and apply domain-specific knowledge while building reasoning logic to guide LLMs toward accurate responses. Our approach tackles three key limitations of current RAG methods:

- Diversity of knowledge sources: Extracting private knowledge and uncovering implicit reasoning from diverse datasets is challenging in industrial applications. PIKE-RAG addresses this by constructing multi-layer heterogeneous graphs, organizing and representing information across different levels of granularity for improved retrieval and inference.
- Inability to balance diverse capabilities with a unified approach: Existing RAG techniques struggle to adapt to the complexities of different use cases. PIKE-RAG’s capability-driven framework categorizes tasks and grades system capabilities, improving adaptability across complex scenarios.
- Insufficient domain-specific knowledge of LLMs: Current methods perform poorly when applied to professional fields, especially where existing LLMs lack proficiency. PIKE-RAG atomizes knowledge and dynamically decomposes tasks, enhancing the LLM’s ability to pull out and organize domain-specific knowledge. It automatically extracts domain knowledge from system interaction logs and refines it through fine-tuning, enabling its application to future queries.
System overview: Constructing a capability-driven solution
PIKE-RAG is multifunctional and scalable. By adjusting submodules within the main modules, it allows for the development of RAG systems that focus on different capabilities. As illustrated in Figure 1, the framework consists of several basic modules, including those that focus on document parsing, knowledge extraction, storage, retrieval, organization, knowledge-centric reasoning, and task decomposition and coordination.
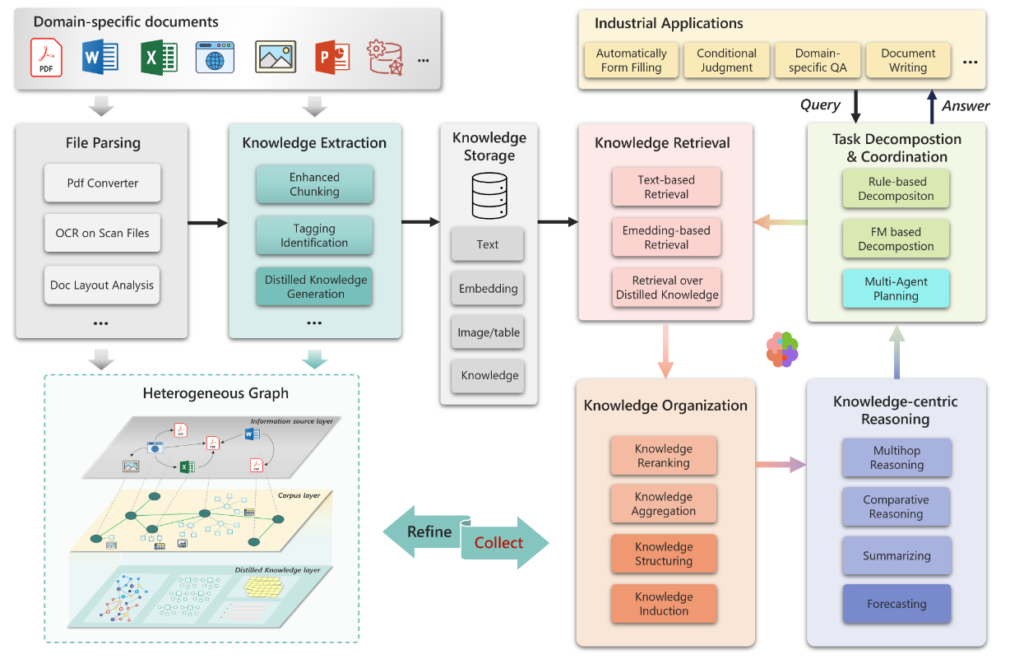
To illustrate PIKE-RAG’s flexibility and power, we present four examples from the medical field that demonstrate how the framework can be adapted to meet diverse real-world needs:
1. Information retrieval: “Query a patient’s medical record on a specific date.”
Challenges: Knowledge extraction and understanding are often hindered by inappropriate segmentation, which disrupts semantic coherence and leads to inefficient data retrieval. Additionally, embedding-based retrieval has limited ability to align professional terms and jargon, reducing system accuracy.
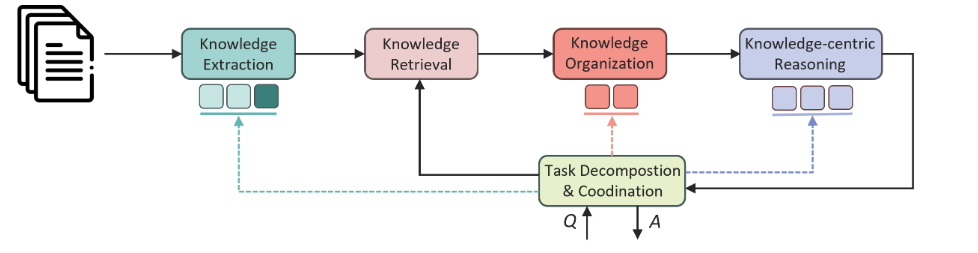
Solution: We improved accuracy by using context-aware segmentation, automated term label alignment, and knowledge extraction methods that support multiple levels of granularity. This is as shown in Figure 2.

2. Information retrieval and linking: “Query and summarize a patient’s medical records from the last five years.”
Building on the previous capability, this task requires not only effective knowledge extraction and utilization but also strong domain-specific knowledge to accurately understand and decompose the task. We added a task decomposition module, extracting and linking relevant knowledge step by step until a final answer is provided, as shown in Figure 3.
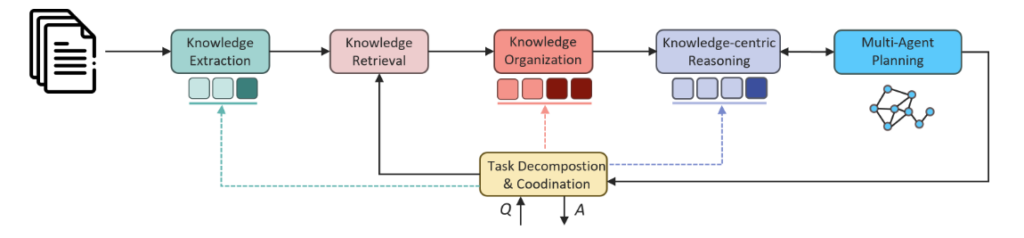
3. Fact-based reasoning and prediction capabilities: “Based on the description of the patient’s condition, predict the most likely disease they may have.”
This task tests the system’s ability to organize, collect, and retrieve information while requiring the LLM to make reasonable inferences based on domain knowledge. As depicted in Figure 4, we enhanced the knowledge organization phase by extracting and organizing structured knowledge, such as mapping standardized symptom descriptions to diagnosed diseases and treatments.
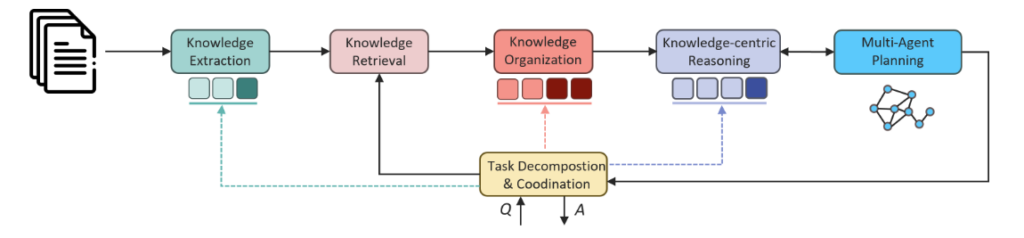
4. Fact-based innovation and generation capability: “Based on the description of the patient’s condition, suggest reasonable treatment plans and coping measures.”
This open-ended task requires high comprehension and the ability to link multiple factors, making it difficult to evaluate the quality of responses. To improve accuracy, we introduced multi-agent planning capabilities, simulating different roles to retrieve knowledge from various perspectives, as shown in Figure 5. For example, in medical diagnosis, intelligent agents representing different specialties can provide more comprehensive treatment recommendations.
These examples demonstrate how PIKE-RAG can be adapted to address increasingly complex tasks in the medical field, ranging from simple retrieval to innovative treatment planning.
Building a knowledge base on multi-level heterogeneous graphs
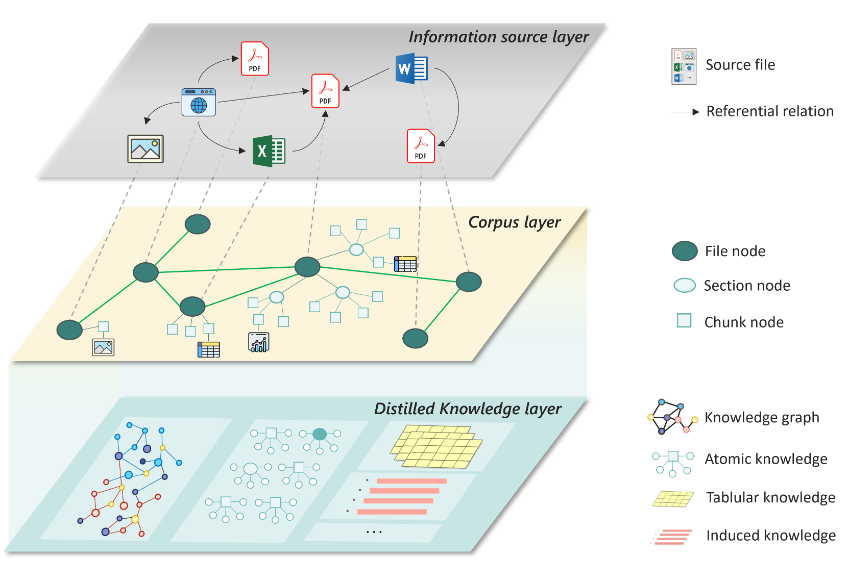
In our previous discussion, we emphasized the importance of constructing a knowledge base multiple times. Now, let’s explore how PIKE-RAG supports the construction and retrieval of a multi-level heterogeneous knowledge base. As illustrated in Figure 6, our approach utilizes a three-layer heterogeneous graph structure, enabling semantic understanding and inference-based retrieval to support various downstream tasks.
- Information source layer
This foundational layer captures diverse information sources, treating them as source nodes and representing their reference relationships through edges. This structure facilitates cross-referencing and contextualization of knowledge, laying the groundwork for inferences that rely on multiple sources. - Corpus layer
Building on the information source layer, this level organizes parsed information into text blocks while retaining the document’s original hierarchical structure. Multi-modal content, such as tables and graphs, is summarized by the LLM and integrated into the knowledge base as block nodes. This approach ensures that multi-modal knowledge is available for retrieval and supports knowledge extraction at different granularities, allowing accurate semantic partitioning and retrieval across various content types. - Distilled knowledge layer
At the top level, the corpus is further refined into structured knowledge forms, including knowledge graphs, atomic knowledge, and structured tabular knowledge. By organizing this distilled information, we enhance the system’s ability to perform deeper domain knowledge inference and synthesis.
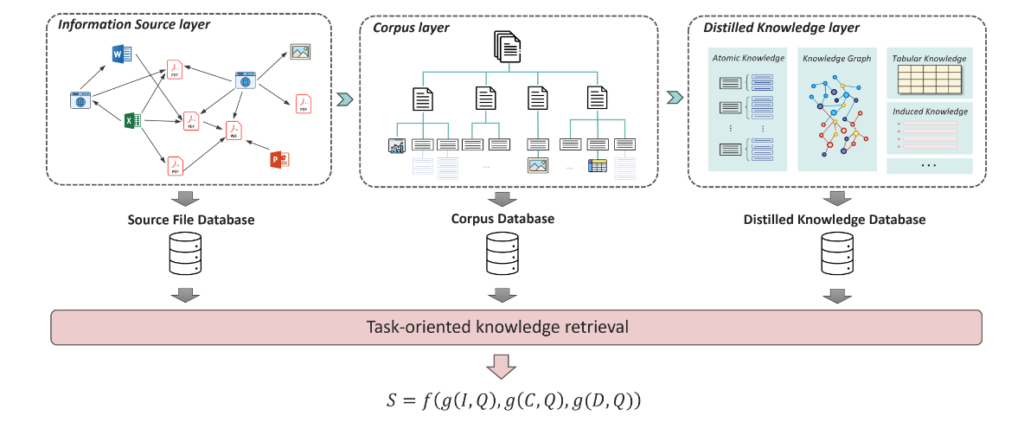
During the retrieval stage, PIKE-RAG considers knowledge from these three levels simultaneously. Beyond typical semantic-level associations, information from both the information source layer and the distilled knowledge layer is used to evaluate the relevance of retrieved knowledge, as shown in Figure 7.
Continuous learning of domain knowledge
While PIKE-RAG primarily relies on existing LLMs for knowledge processing and task completion, it also addresses the challenge of incorporating valuable private data, particularly in specialized fields like medicine.
PIKE-RAG includes modules supporting the following self-development and learning capabilities:
1. Periodic log analysis: The system analyzes operation logs to extract expert feedback, which is used to fine-tune the LLM.
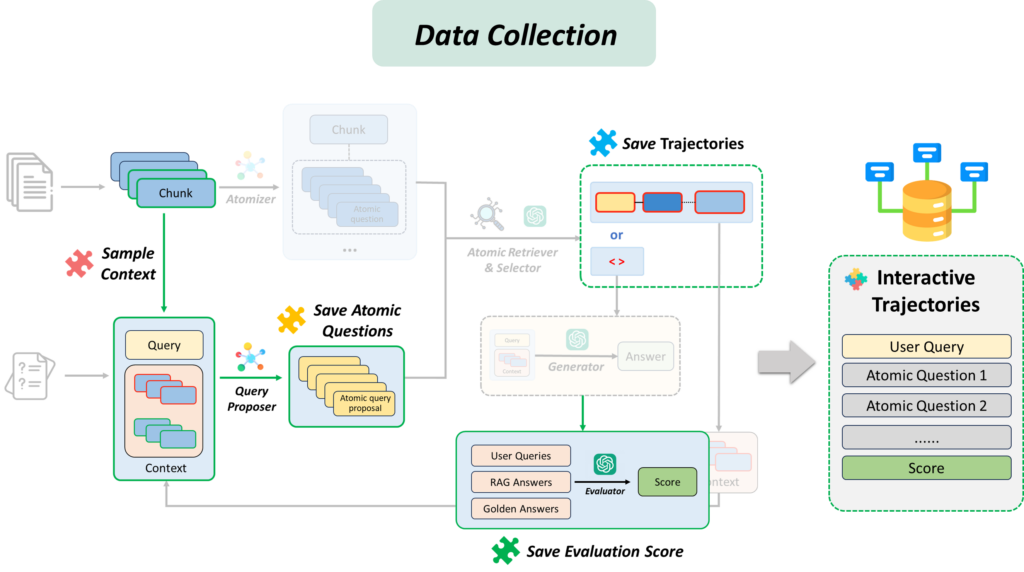
2. Automated data collection: To address the inefficiency and cost of expert feedback, this module employs an iterative learning process. For incorrectly answered questions, the system tries different knowledge extraction and retrieval strategies. It then evaluates the effectiveness of each strategy based on the accuracy of the answers produced.
3. Continuous improvement: Successful strategies are saved and used to fine-tune the LLM. Through this process, the system continuously improves during operation, constantly acquiring domain-relevant knowledge and experience.
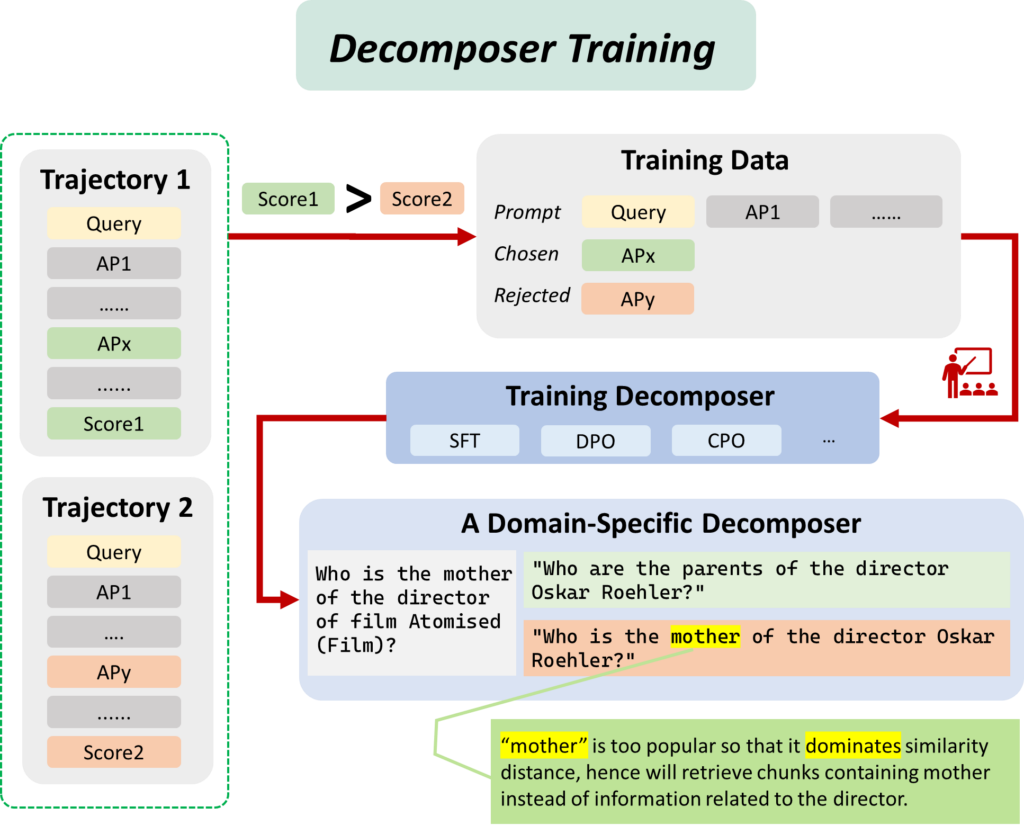
Figures 8 and 9 show the data collection process and how collected data is used to fine-tune task decomposition components.
Evaluating PIKE-RAG
In public benchmark tests, PIKE-RAG has demonstrated excellent performance on several multi-hop question-answering datasets, outperforming existing benchmark methods in metrics such as accuracy and F1 score:
- HotpotQA: 87.6% accuracy and 76.26% F1
- 2WikiMultiHopQA: 82.0% accuracy and 75.19% F1
- MuSiQue (more challenging): 59.6% accuracy and 56.62% F1
These results underscore PIKE-RAG’s proficiency in handling complex reasoning tasks, particularly in scenarios requiring integration of multi-source information and multi-step reasoning.
Looking ahead
In research experiments, PIKE-RAG shows significant improvements in question answering accuracy across industrial manufacturing, mining, and pharmaceutical sectors. Our future research will focus on:
- Expanding applications to additional specialized fields
- Exploring innovative forms of knowledge representation and logical reasoning tailored to specific scenarios
- Developing more efficient model alignment and fine-tuning methods to integrate specific knowledge and logic into existing models with less data
By pursuing these directions, we aim to enhance PIKE-RAG’s capabilities and broaden its applicability across even more diverse industrial domains, ultimately bridging the gap between general-purpose LLMs and tasks that require specialized knowledge.



