

微软亚洲研究院
新闻与深度文章

编者按:每年的9月21日是“世界阿尔茨海默病日”,阿尔茨海默病作为最常见的认知障碍,一直以来都备受关注。研究证明,科学的认知训练可以起到对该疾病的预防和延缓。为此,微软亚洲研究院与上海市精神卫生中心携手展开联合研究,基于微软 Azure OpenAI 服务中的多模态大模型,开发了利用多种模态数据(如语音、文字、图片、音乐等信息)的个性化认知训练框架,为认知障碍患者的认知训练带来了新的可能。 随着全…

编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。 本期,我们为大家精心挑选了4篇论文,内容涵盖金融市场元智能体模型、大语言模型的结构化剪枝、多模态感知中的模态对齐以及 AI 芯片的深度学习编译器,感兴趣的朋友快来看看吧! 本期内容速览 01. 通过扩展式模态…

作者:机器学习组 编者按:研究与开发(R&D)是推动社会进步、经济增长和技术创新的核心动力。在人工智能时代,如何充分激发大语言模型的潜力,通过自动化手段提升研究与开发效率,实现跨领域知识迁移与创新,已成为 R&D 智能化转型的关键。为应对这一挑战,微软亚洲研究院推出了自动化研究与开发工具 RD-Agent,依托大语言模型的强大能力,开创了以人工智能驱动 R&D 流程自动化的…

作者:刘树杰 编者按:文本到语音合成(Text-to-Speech,TTS)是一种将书面文字转化为自然语音的技术,在提高无障碍性、增强跨语言交流等方面发挥着重要作用。微软亚洲研究院此前推出了第一个离散编码的语音大模型 VALL-E,并在此基础上通过重复感知采样和分组编码建模技术将其升级为 VALL-E 2 版本。新版本突破了语音稳健性、自然度和说话人相似度方面的界限,让零样本 TTS 性能在 Li…

编者按:当前多模态模型大致分为两类,一类是专用多模态模型,如文本生成图像、文本生成视频等;另一类则是通用型多模态大语言模型,这类模型的目标是让人工智能具备自然语言理解和生成、图像识别,以及语音和视频的交互能力。近日,微软亚洲研究院又提供了一个新的选择——原生多模态大语言模型。它能够更深入地理解物理世界并执行多模态推理和跨模态迁移,其在不同模态的数据学习中还涌现出了新的能力。 随着人工智能技术的持续…

作者:工程与基础架构组 编者按:代码大语言模型(Code LLMs)作为大语言模型与编程领域结合的产物,可以通过自动生成和补全代码帮助开发者快速实现功能。但目前针对代码大语言模型的指令微调方法主要集中在传统的代码生成任务上,忽略了模型在处理复杂多任务场景中的表现。为此,来自微软亚洲研究院的研究员们开发了 WaveCoder 模型,其使用包含19,915个指令、涵盖4个代码任务的数据集 CodeSe…

作者:机器学习组 编者按:随着数据量和模型规模的增加,大语言模型在指令执行、知识存储、逻辑推理和编程技能等方面展现出了突破性的能力。然而,大语言模型在产业领域的潜能尚未得到充分挖掘,特别是在满足产业数据分析、推理、预测、决策等数据智能需求方面。如何有效地变革各行业的数据模型及智能的构建方法与应用范式,仍然面临诸多挑战。为应对这些挑战,微软亚洲研究院提出了构建产业基础模型的倡议,其核心理念在于通过持…

人工智能技术正在不断突破我们的想象空间,并逐渐成为推动社会变革和科技进步的核心力量。在即将到来的 Microsoft Research Forum 第四期中,来自微软研究院不同实验室的研究员们将带大家了解最新的多模态 AI 模型、先进的 AI 评估基准和模型自我改进技术,以及全新的 AI 推理和复杂优化计算机,并与大家共同探讨 AI 模型将如何助力从天气预测到材料设计等各领域的进步。 本期 Mic…
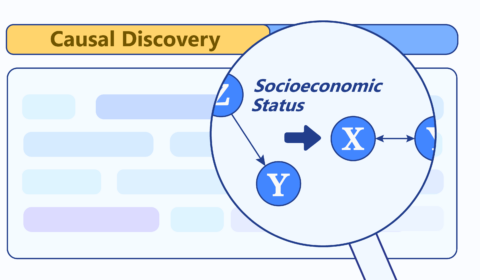
作者:DKI组 编者按:在当今数据驱动的世界,理解复杂系统中的因果关系是科学研究和实际应用中的关键挑战。在人工智能领域,因果推理能力更是成为一个热门话题。如何揭示数据背后因果机制的关键?如何利用数据实现因果发现的突破?为回答这些问题,来自微软 DKI(Data, Knowledge and Intelligence,数据、知识与智能)领域的研究员们在进行了持续而深入的探索,其相关成果发表在 AAA…