
Distillation and Pruning for Scalable Self-Supervised Representation-Based Speech Quality Assessment
- Benjamin Stahl ,
- Hannes Gamper
2025 International Conference on Acoustics, Speech, and Signal Processing |
Distill-MOS is a compact and efficient speech quality assessment model learned from a larger speech quality assessment model based on wav2vec2.0 XLS-R embeddings. Model weights and inference code are available on GitHub (opens in new tab).
Install Distill-MOS via
pip install distillmos
The work is described in the paper: «Distillation and Pruning for Scalable Self-Supervised Representation-Based Speech Quality Assessment».
Abstract:
In this paper, we investigate distillation and pruning methods to reduce model size for non-intrusive speech quality assessment based on self-supervised representations. Our experiments build on XLS-R-SQA, a speech quality assessment model using wav2vec 2.0 XLS-R embeddings. We retrain this model on a large compilation of mean opinion score datasets, encompassing over 100,000 labeled clips. For distillation, using this model as a teacher, we generate pseudo-labels on unlabeled degraded speech signals and train student models of varying sizes. For pruning, we use a data-driven strategy. While data-driven pruning performs better at larger model sizes, distillation on unlabeled data is more effective for smaller model sizes. Distillation can halve the gap between the baseline’s correlation with ground-truth MOS labels and that of the XLS-R-based teacher model, while reducing model size by two orders of magnitude compared to the teacher model.
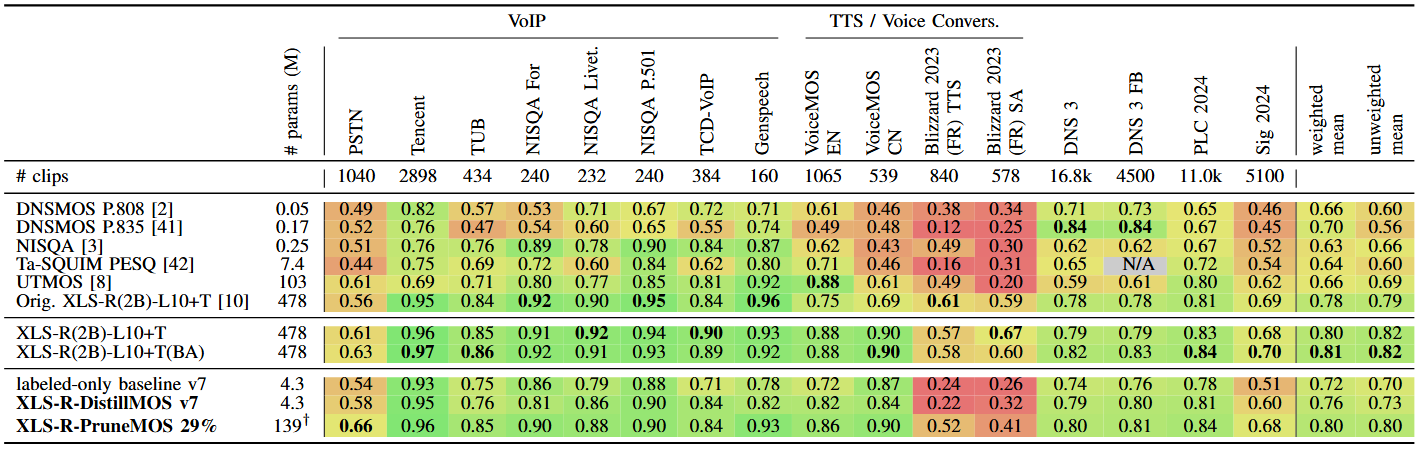
Table summarizing speech quality estimation results
 GitHub
GitHub