

New whitepaper outlines the taxonomy of failure modes in AI agents
We are releasing a taxonomy of failure modes in AI agents to help security professionals and machine learning engineers think through how AI systems can fail and design them with safety and security in mind.
The taxonomy continues Microsoft AI Red Team’s work to lead the creation of systematization of failure modes in AI; in 2019, we published one of the earliest industry efforts enumerating the failure modes of traditional AI systems. In 2020, we partnered with MITRE and 11 other organizations to codify the security failures in AI systems as Adversarial ML Threat Matrix, which has now evolved into MITRE ATLAS™. This effort is another step in helping the industry think through what the safety and security failures in the fast-moving and highly impactful agentic AI space are.
Taxonomy of Failure Mode in Agentic AI Systems
Microsoft's new whitepaper explains the taxonomy of failure modes in AI agents, aimed at enhancing safety and security in AI systems.

To build out this taxonomy and ensure that it was grounded in concrete and realistic failures and risk, the Microsoft AI Red Team took a three-prong approach:
- We catalogued the failures in agentic systems based on Microsoft’s internal red teaming of our own agent-based AI systems.
- Next, we worked with stakeholders across the company—Microsoft Research, Microsoft AI, Azure Research, Microsoft Security Response Center, Office of Responsible AI, Office of the Chief Technology Officer, other Security Research teams, and several organizations within Microsoft that are building agents to vet and refine this taxonomy.
- To make this useful to those outside of Microsoft, we conducted systematic interviews with external practitioners working on developing agentic AI systems and frameworks to polish the taxonomy further.
To help frame this taxonomy in a real-world application for readers, we also provide a case study of the taxonomy in action. We take a common agentic AI feature of memory and we walk through how an cyberattacker could corrupt an agent’s memory and use that as a pivot point to exfiltrate data.
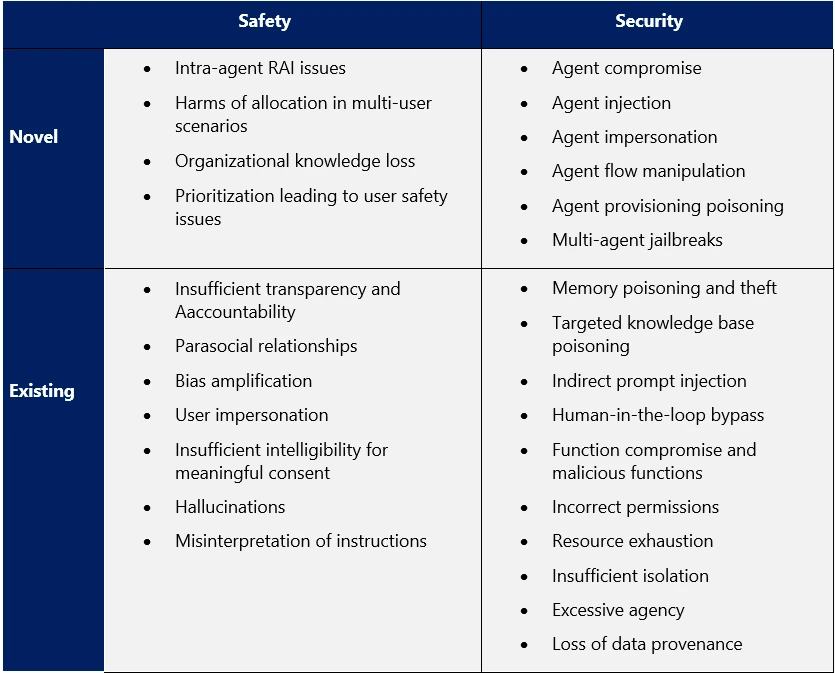
Figure 1. Failure modes in agentic AI systems.
Core concepts in the taxonomy
While identifying and categorizing the different failure modes, we broke them down across two pillars, safety and security.
- Security failures are those that result in core security impacts, namely a loss of confidentiality, availability, or integrity of the agentic AI system; for example, such a failure allowing a threat actor to alter the intent of the system.
- Safety failure modes are those that affect the responsible implementation of AI, often resulting in harm to the users or society at large; for example, a failure that causes the system to provide differing quality of service to different users without explicit instructions to do so.
We then mapped the failures along two axes—novel and existing.
- Novel failure modes are unique to agentic AI and have not been observed in non-agentic generative AI systems, such as failures that occur in the communication flow between agents within a multiagent system.
- Existing failure modes have been observed in other AI systems, such as bias or hallucinations, but gain in importance in agentic AI systems due to their impact or likelihood.
As well as identifying the failure modes, we have also identified the effects these failures could have on the systems they appear in and the users of them. Additionally we identified key practices and controls that those building agentic AI systems should consider to mitigate the risks posed by these failure modes, including architectural approaches, technical controls, and user design approaches that build upon Microsoft’s experience in securing software as well as generative AI systems.
The taxonomy provides multiple insights for engineers and security professionals. For instance, we found that memory poisoning is particularly insidious in AI agents, with the absence of robust semantic analysis and contextual validation mechanisms allows malicious instructions to be stored, recalled, and executed. The taxonomy provides multiple strategies to combat this, such as limiting the agent’s ability to autonomously store memories by requiring external authentication or validation for all memory updates, limiting which components of the system have access to the memory, and controlling the structure and format of items stored in memory.
How to use this taxonomy
- For engineers building agentic systems:
- We recommend that this taxonomy is used as part of designing the agent, augmenting the existing Security Development Lifecycle and threat modeling practice. The guide helps walk through the different harms and the potential impact.
- For each harm category, we provide suggested mitigation strategies that are technology agnostic to kickstart the process.
- For security and safety professionals:
- This is a guide on how to probe AI systems for failures before the system launches. It can be used to generate concrete attack kill chains to emulate real world cyberattackers.
- This taxonomy can also be used to help inform defensive strategies for your agentic AI systems, including providing inspiration for detection and response opportunities.
- For enterprise governance and risk professionals, this guide can help provide an overview of not just the novel ways these systems can fail but also how these systems inherit the traditional and existing failure modes of AI systems.
Learn more
Like all taxonomies, we consider this a first iteration and hope to continually update it, as we see the agent technology and cyberthreat landscape change. If you would like to contribute, please reach out to [email protected].
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the latest news and updates on cybersecurity.
The taxonomy was led by Pete Bryan; the case study on poisoning memory was led by Giorgio Severi. Others that contributed to this work: Joris de Gruyter, Daniel Jones, Blake Bullwinkel, Amanda Minnich, Shiven Chawla, Gary Lopez, Martin Pouliot, Whitney Maxwell, Katherine Pratt, Saphir Qi, Nina Chikanov, Roman Lutz, Raja Sekhar Rao Dheekonda, Bolor-Erdene Jagdagdorj, Eugenia Kim, Justin Song, Keegan Hines, Daniel Jones, Richard Lundeen, Sam Vaughan, Victoria Westerhoff, Yonatan Zunger, Chang Kawaguchi, Mark Russinovich, Ram Shankar Siva Kumar.