
規模化的多語言翻譯:10000 對語言及更多
微軟正在尋找 規模化的 AI 以極高的雄心壯志實現下一代的 AI 體驗。微軟翻譯器 ZCode 團隊與 微軟圖靈專案 與微軟亞洲研究院共同推動語言與多語言支援,是這項計畫的核心。我們持續以多語模式推進前沿技術,以支援整個微軟的各種語言情境。去年夏天,我們宣佈了大規模的 專家的多語言混合 型號與 深度加速 可超越個別大型雙語模型。最近,最新的圖靈通用語言表示模型 (T-ULRv5),微軟創建的模型再次成為最先進的技術,並在 Google XTREME 公開排行榜 當時。最近,微軟宣佈了最大的 Megatron-Turing NLG 530B 參數模型。
一年一度的機器翻譯大會(又稱 WMT 2021)上週在美麗的多明尼加共和國蓬塔卡納落下帷幕。WMT 匯集了整個機器翻譯領域的研究人員,包括業界和學術界,共同參與一系列的共同任務,每項任務都定義了機器翻譯重要領域的基準,將該領域推向新的前沿。
微軟翻譯器 ZCode 團隊與 Turing 團隊和微軟亞洲研究院合作,參加了「大規模多語言翻譯」賽道的競賽,其中包括一項在 101 種語言的所有 10,000 個方向之間進行翻譯的完整任務,以及兩項小型任務:一項專注於 5 種中南歐語言,另一項專注於 5 種東南亞語言。Microsoft ZCode-DeltaLM 模型以極大的優勢贏得了所有三項任務,包括在以 10,000 對語言進行評估的大型任務中,比 M2M100 模型高出令人難以置信的 10 多分。(WMT 2021 年大型多語言機器翻譯共同任務的結果, Wenzek 等人,WMT 2021)。

圖 1:WMT 2021 大規模多語翻譯共同任務中 Full-Task 和 Small-Task1 的正式結果(BLEU 分數
ZCode-DeltaLM 方法
在這篇部落格文章中,讓我們來看看勝出的 Microsoft ZCode-DeltaLM 模型。我們的起點是 DeltaLM (DeltaLM:透過增強預先訓練的多語言編碼器,為語言生成和翻譯進行編碼器-解碼器預訓練),是微軟功能日益強大的大型多語言預訓語言模型系列中的最新產品。

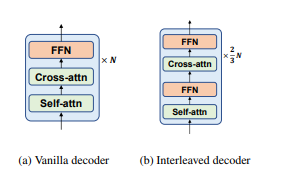
DeltaLM 是一個編碼器-解碼器模型,但不是從頭開始訓練,而是從先前預先訓練的最先進純編碼器模型初始化,具體來說是 (TULRv3).雖然編碼器的初始化很簡單,但是解碼器就沒那麼簡單了,因為它會在編碼器的自注意之外加上交叉注意。DeltaLM 使用新穎的交錯架構解決了這個問題,在這個架構中,自注意和交叉注意在各層之間交替使用,奇數層使用自注意,偶數層使用交叉注意。透過這種交錯方式,解碼器的結構與編碼器相匹配,因此也可以同樣的方式從 TULRv3 初始化。
DeltaLM 由 ZCode 強大的多任務學習功能所增強: 多語言神經機器翻譯的多任務學習.我們的模型顯示,結合多任務與多語言學習,可以大幅改善大規模預訓語言模型的訓練。這種多任務多語言學習範例可同時利用來自多種任務與語言的歸納偏差與正則化,在各種下游任務上有更好的表現。如下圖所示,我們使用翻譯任務、去噪自動編碼器任務和翻譯跨度損壞任務。

贏得大規模多語言翻譯軌道
建立我們獲勝的大型多語言翻譯系統 (微軟為 WMT21 共用任務提供的多語言機器翻譯系統),我們從 zCode-DeltaLM 開始,並加入一些技巧。
我們採用漸進式學習,首先訓練一個有 24 個編碼層和 12 個解碼層的模型,然後繼續訓練 12 個新增的編碼層,最後產生一個深度 36 層編碼器。為了涵蓋所有語言對,我們產生雙假平行資料,其中平行資料的兩邊都是合成的,由模型從英文翻譯過來。我們也運用迭代反向翻譯來產生合成資料。我們應用課程學習,從整個嘈雜的訓練資料開始,然後將其減少為乾淨的子集。我們重新調整翻譯目標的權重,使平行資料優於回譯和雙假平行資料。我們應用溫度取樣來平衡各語言對。對於每個語言對,我們會根據 dev 集選擇是傾向於直接翻譯還是透過英文進行樞軸翻譯。
將這些結合起來,我們知道我們擁有一個令人驚嘆的大型多語言系統,但在盲測集上的正式結果超出了我們的預期。我們的 BLEU 分數比下一位競爭者高出 2.5 到 9 分,比基準 M2M-175 機型高出 10 到 21 個 BLEU 點。在 dev 測試中,我們與較大的 M2M-615 機型進行比較,也勝出 10 到 18 分。

超越翻譯:通用語言生成
雖然我們對於在 WMT 2021 獲得大獎感到興奮,但更令人興奮的是,與其他競爭對手不同,我們的 ZCode-DeltaLM 模型不僅是一個翻譯模型,而是一個通用的預訓編碼器-解碼器語言模型,可用於翻譯以外的各種生成任務。這確實使我們的模型在各種多語言自然語言生成任務上有相當好的表現。
我們在許多流行的世代任務中達到了新的 SOTA,從 GEM 基準包括 Wikilingua (摘要)、文字簡化 (WikiAuto) 和結構轉文字 (WebNLG)。DeltaLM-ZCode 模型的表現遠遠優於更大型的模型,例如 mT5 XL (3.7B),它也是在更大型的資料上訓練出來的。這證明了模型的效率和多功能性,在許多任務上都有強大的表現。

圖 2.ZCode-DeltaLM 在 GEM 基準中總結及簡化文字任務的效能 (RL 得分)
展望未來
多語言機器翻譯在低資源和高資源語言上的表現都已達到超越雙語系統的地步。專家混合 (MoE) 模型已被證明非常適合擴展此類模型,正如 GShard 所顯示的。我們將探討如何利用專家混合模型來有效地擴展此類模型: 適用於多任務多語言模型的可擴展性和高效的 MoE 訓練.具有大量多語言資料和無監督多任務訓練的 MoE 模型提供了前所未有的機會,讓此類模型能夠提供真正的通用系統,進一步讓 Microsoft 翻譯器團隊消除全球各地的語言障礙,並支援各種自然語言生成任務。
鳴謝
我們要感謝 Francisco Guzman 及其團隊,他們收集了大量多語言的 FLORES 測試集並組織了這個 WMT 賽道,進行如此大規模的評估。



